今天主要带大家来实操学习下Pandas,因为篇幅原因,分为了两部分,本篇为上。

1数据结构的简介
pandas中有两类非常重要的数据结构,就是序列Series和数据框类似于NumPy中的一维数组,可以使用一维数组的可用函数和方法,而且还可以通过索引标签的方式获取数据,还具有索引的自动对齐功能;DataFrame类似于numpy中的二维数组,同样可以使用numpy数组的函数和方法,还具有一些其它灵活的使用。
1.1Series的创建三种方法
通过一维数组创建序列m
importpandasaspdimportnumpyasnparr1=(10)print("数组arr1:",arr1)print("arr1的数据类型:",type(arr1))s1=(arr1)print("序列s1:",s1)print("s1的数据类型:",type(s1))数组arr1:[0123456789]arr1的数据类型:class''序列s1:00112233445566778899dtype:int32s1的数据类型:class''
通过字典的方式创建序列
dict1={'a':1,'b':2,'c':3,'d':4,'e':5}print("字典dict1:",dict1)print("dict1的数据类型:",type(dict1))s2=(dict1)print("序列s2:",s2)print("s2的数据类型:",type(s2))字典dict1:{'a':1,'b':2,'c':3,'d':4,'e':5}dict1的数据类型:class'dict'序列s2:a1b2c3d4e5dtype:int64s2的数据类型:class''通过已有DataFrame创建
由于涉及到了DataFrame的概念,所以等后面介绍了DataFrame之后补充下如何通过已有的DataFrame来创建Series。
1.2DataFrame的创建三种方法
通过二维数组创建数据框
print("第一种方法创建DataFrame")arr2=((12)).reshape(4,3)print("数组2:",arr2)print("数组2的类型",type(arr2))df1=(arr2)print("数据框1:",df1)print("数据框1的类型:",type(df1))第一种方法创建DataFrame数组2:[[012][345][678][91011]]数组2的类型class''数据框1:0120012011数据框1的类型:class''
通过字典列表的方式创建数据框
print("第二种方法创建DataFrame")dict2={'a':[1,2,3,4],'b':[5,6,7,8],'c':[9,10,11,12],'d':[13,14,15,16]}print("字典2-字典列表:",dict2)print("字典2的类型",type(dict2))df2=(dict2)print("数据框2:",df2)print("数据框2的类型:",type(df2))第二种方法创建DataFrame字典2-字典列表:{'a':[1,2,3,4],'b':[5,6,7,8],'c':[9,10,11,12],'d':[13,14,15,16]}字典2的类型class'dict'数据框2:abcd0423711153481216数据框2的类型:class''通过嵌套字典的方式创建数据框
dict3={'one':{'a':1,'b':2,'c':3,'d':4},'two':{'a':5,'b':6,'c':7,'d':8},'three':{'a':9,'b':10,'c':11,'d':12}}print("字典3-嵌套字典:",dict3)print("字典3的类型",type(dict3))df3=(dict3)print("数据框3:",df3)print("数据框3的类型:",type(df3))字典3-嵌套字典:{'one':{'a':1,'b':2,'c':3,'d':4},'two':{'a':5,'b':6,'c':7,'d':8},'three':{'a':9,'b':10,'c':11,'d':12}}字典3的类型class'dict'数据框3:onethreetwoa195b2106c3117d4128数据框3的类型:class''有了DataFrame之后,这里补充下如何通过DataFrame来创建Series。
s3=df3['one']df3['a']如果不给序列一个指定索引值,序列会自动生成一个从0开始的自增索引
011223344556dtype:int32
通过index属性获取序列的索引值
RangeIndex(start=0,stop=6,step=1)
为index重新赋值
=['a','b','c','d','e','f']s5
a1b2c3d4e5f6dtype:int32
通过索引获取数据
s5[3]4
s5['e']5
s5[[1,3,5]]b2d4f6dtype:int32
s5[:4]a1b2c3d4dtype:int32
s5['c':]c3d4e5f6dtype:int32
s5['b':'e']当对两个s6=(([10,15,20,30,55,80]),index=['a','b','c','d','e','f'])print("序列6:",s6)s7=(([12,11,13,15,14,16]),index=['a','c','g','b','d','f'])print("序列7:",s7)print(s6+s7)可以注意到这里的算术运算自动实现了两个序列的自动对齐test_(['ID'],inplace=True,axis=1)test_()
非数值值特征数值化
test_data['job'],jnum=(test_data['job'])test_data['job']=test_data['job']+1test_data['marital'],jnum=(test_data['marital'])test_data['marital']=test_data['marital']+1test_data['education'],jnum=(test_data['education'])test_data['education']=test_data['education']+1test_data['default'],jnum=(test_data['default'])test_data['default']=test_data['default']+1test_data['housing'],jnum=(test_data['housing'])test_data['housing']=test_data['housing']+1test_data['loan'],jnum=(test_data['loan'])test_data['loan']=test_data['loan']+1test_data['contact'],jnum=(test_data['contact'])test_data['contact']=test_data['contact']+1test_data['month'],jnum=(test_data['month'])test_data['month']=test_data['month']+1test_data['poutcome'],jnum=(test_data['poutcome'])test_data['poutcome']=test_data['poutcome']+1test_()

查询数据的前5行
test_()

查询数据的末尾5行
test_()

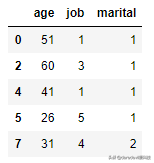
查询指定的行
test_[[0,2,4,5,7]]

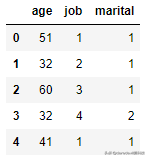
查询指定的列
test_data[['age','job','marital']].head()
查询指定的行和列
test_[[0,2,4,5,7],['age','job','marital']]
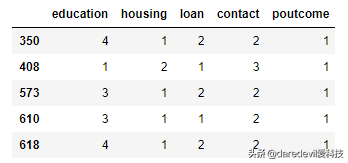
查询年龄为51的信息
只选取housing,loan,contac和poutcometest_data[(test_data['age']==51)(test_data['job']=5)][['education','housing','loan','contact','poutcome']].head()

可以看到,当有多个条件的查询,需要在或者|的两端的条件括起来
4对DataFrames进行统计分析
Pandas为我们提供了很多描述性统计分析的指标函数,包括,总和,均值,最小值,最大值等。
a=(size=10)d1=(2*a+3)d2=(2,4,size=10)d3=(1,100,size=10)print(d1)print(d2)print(d3)
05.81107712.96341822.29507830.27964746.56429351.14645561.90362371.15771082.92130492.397009dtype:float64[0.181473960.482189620.425659030.102589420.552998420.108593280.669231991.185420090.120530794.64172891][338416923]
非空元素的计算
()10
最小值
()0.61872
最大值
()6.2818
最小值的位置
()8
最大值的位置
()1
10%分位数
(0.1)1.854274
求和
()27.43961378467516
平均数
()2.743961378467515
中位数
()2.3460435427041384
众数
()00.27964711.14645521.15771031.90362342.29507852.39700962.92130472.96341885.81107796.564293dtype:float64
方差
()4.027871738323722
标准差
()2.0069558386580715
平均绝对偏差
()1.456849211331346
偏度
()1.0457755613918738
峰度
()0.39322767370407874
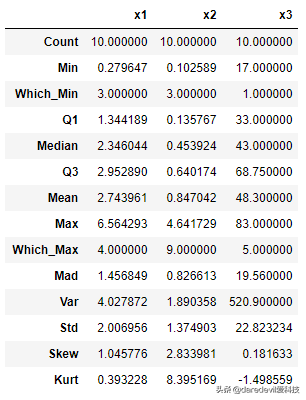
一次性输出多个描述性统计指标
()%1.34418950%2.34604475%2.952890:float64
当实际工作中我们需要处理的是一系列的数值型数据框,可以使用apply函数将这个stats函数应用到数据框中的每一列df=(([d1,d2,d3]).T,columns=['x1','x2','x3'])test_(['ID'],inplace=True,axis=1)train_()
train_data['job'].describe()数值型数据的描述%3.00000050%6.00000075%8.000000:job,dtype:float64
除了以上简单的描述性统计之外,还提供了连续变量的相关系数(corr)和协方差(cov)的求解
df